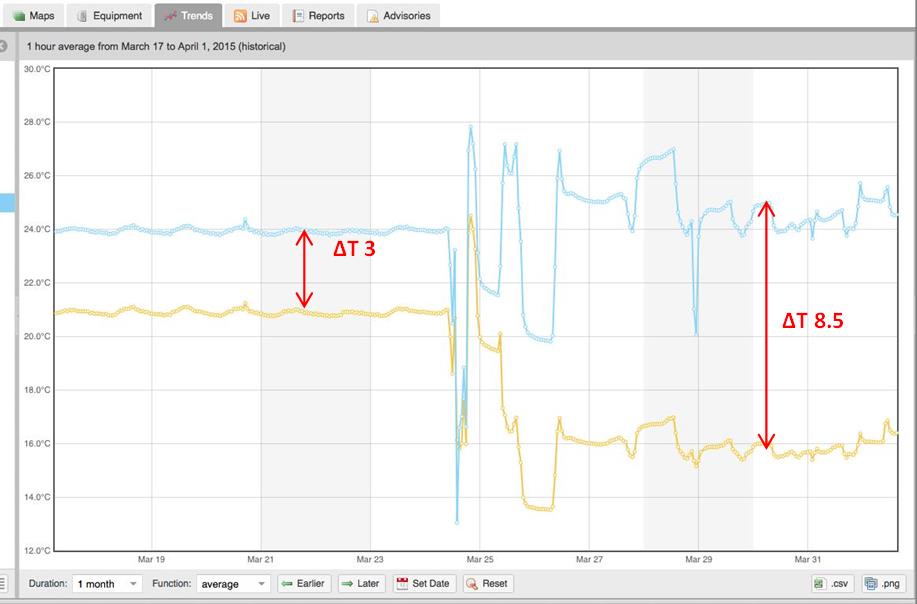
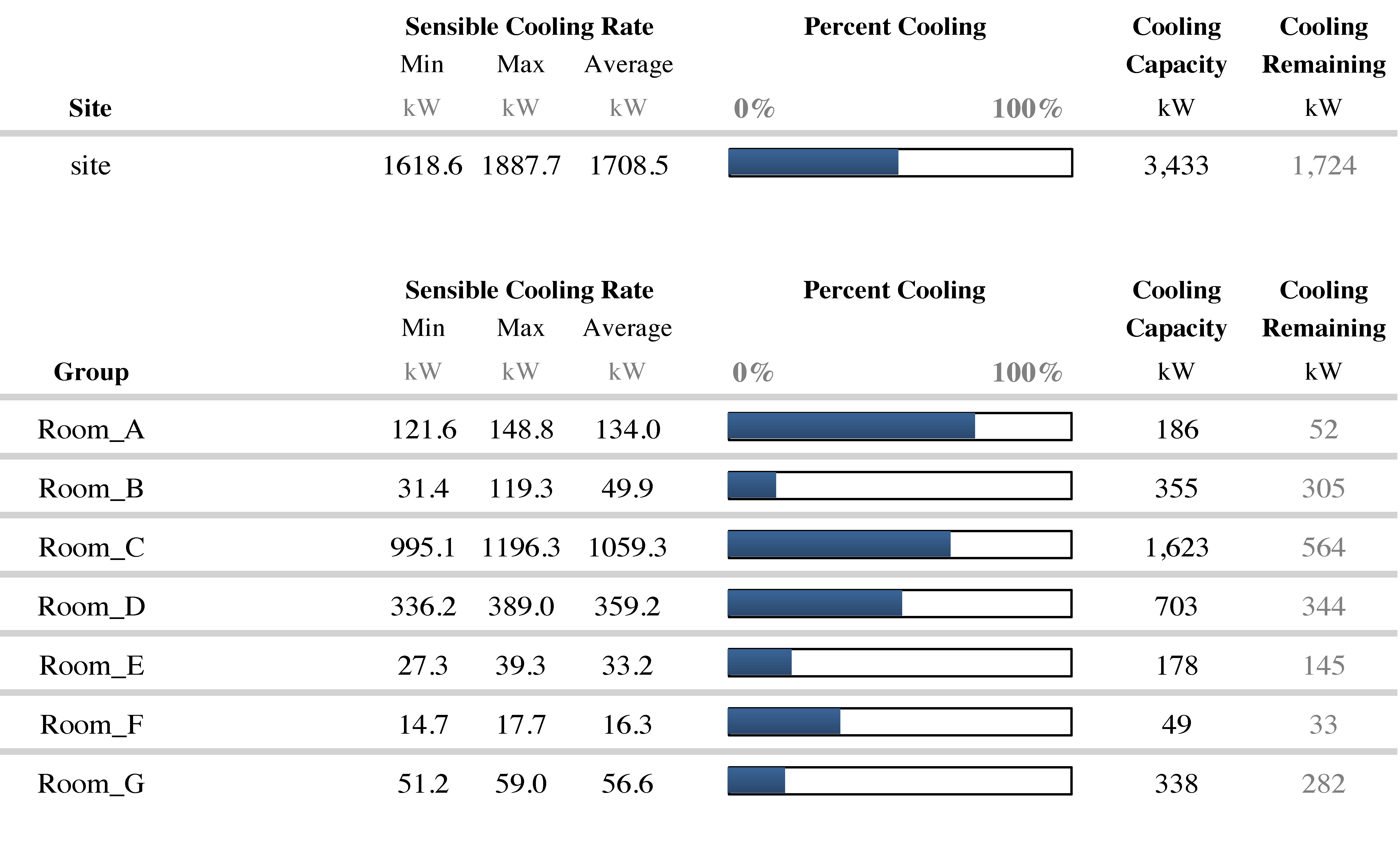
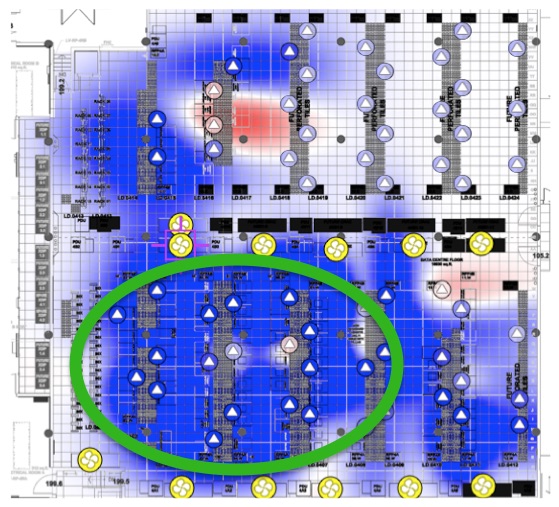
A recent McKinsey & Company Global Institute report states that that factories, including industrial facilities and data centers, will receive the lion’s share of value enabled by IoT. That’s up to $3.7 trillion dollars of incremental value over the next ten years. Within that focus, McKinsey states that the areas of greatest potential are optimization and predictive maintenance – things that every data center facility manager addresses on a daily basis. The report also states that Industrial IoT (combining the strength of both industry and the Internet) will accelerate global GDP per capita to a pace never seen before during the industrial and Internet revolutions.
The McKinsey study described key enablers required for the success of Industrial IoT as: software and hardware technology, interoperability, security and privacy, business organization and cultural support. Translated into the requirements for a data center, these are: low power & inexpensive sensors, mesh connectivity, smart software to analyze and act on the data (analytics), standardization and APIs across technology stacks, interoperability across vendors, and ways to share data that retain security and privacy.
Many of these enabling factors are readily available today. Data centers must have telemetry and communications. If you don’t have it, you can add it in the form of mesh network sensors. Newer data centers and equipment will have this telemetry embedded. The data center industry already has standards that can be used to share data. Smart software capable of aggregating, analyzing and acting on this data is also available. Security isn’t as well evolved, or understood. As more data becomes available through the Internet of Things, the network must be secure, private and locked down.
Transitions always involve change, and sometimes challenge the tried and true ways of doing things. In the case of industrial IoT, I really think that change is good. Telemetry and analytics reveal previously hidden information and patterns that will help facility professionals develop even more efficient processes. Alternately, it may help these same professionals prove to their executive management that existing processes are working very well. The point is that to date, no one has known for sure, because the data just hasn’t been available.
The emergence of IoT in the data center is inevitable, and facility managers who embrace this change and use it to their operational advantage can turn their attention to more strategic projects.
My next blog will address how telemetry and IoT can break down the traditional conflicts between facilities, IT and sustainability managers.
Stay tuned.