
In October the CDC confirmed what many in the scientific community have been saying for months: airborne transmission of SARS-CoV-2 is one of the primary mechanisms of infection. In addition to social distancing, mask wearing, and hand washing, experts now recommend increasing the ventilation and filtration of indoor air.
Despite widespread consensus on this approach, there are no published guidelines for the combined levels ofventilation, filtration, and other actions required to control the pandemic. This is an urgent concern because colder weather in the Northern Hemisphere has moved social activity indoors where the risk of infection is higher.
In response to this need, I wrote a paper that lays out a healthy buildings recommendation (“Guideline”) for operating heating, ventilation and air conditioning (HVAC) systems in indoor spaces (buildings, trains, aircraft). If applied broadly, the Guideline would result in a decrease in the number of infections and help end the pandemic. Of course, the Guideline does not preclude more aggressive measures aimed at protecting vulnerable groups, such as senior citizens or people with compromised immune systems. The Guideline takes into account the use of personal protective equipment (facemasks) and administrative controls (occupant density) so that its requirement for HVAC systems can be more readily achieved.
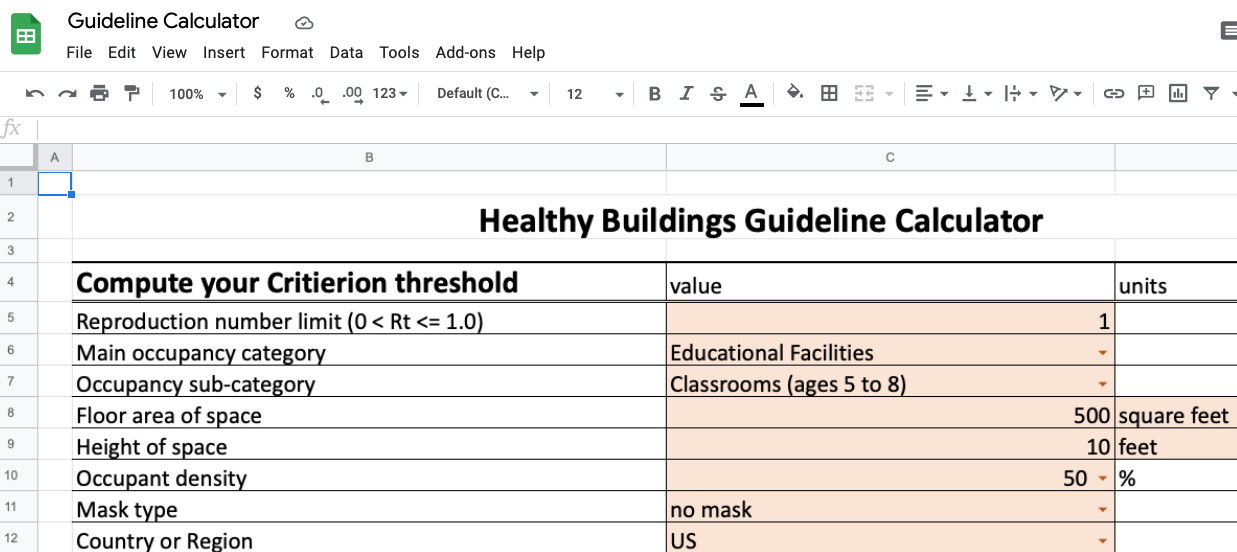
To make the concepts in the paper more accessible to practitioners, I created a Google Sheet that calculates the threshold required (“Criterion”) to meet the Guideline, and also calculates whether or not an indoor environment is meeting the Criterion.
The new coronavirus emerged in late 2019, quickly spread around the world, and changed our lives. Working from home is now standard practice, many commercial buildings are sitting empty, and classes are conducted remotely by videoconference.
The Guideline calculator requires only five inputs to compute the Criterion:
- occupancy category
- size of the space
- occupant density
- type of facemask worn by occupants
- location of the indoor space
To calculate whether or not the space complies with the Guideline, users need to provide the following additional information:
- outdoor air fraction (or flow rate if using a dedicated outdoor air system)
- filter MERV rating
- supply airflow rate to the occupied space
- performance of ultraviolet germicidal irradiation (UVGI, if present)
- indoor temperature
- relative humidity
My hope is that the Guideline will be adopted by organizations such as ASHRAE and REHVA so that building owners and operators, and the consultants who work for them, will know how to most effectively minimize risk to occupants as we deal with the pandemic and promote healthy buildings.



