Hands in the network cause problems. A setting adjusted once, based on someone’s instinct of what needed to be changed at one moment in time, is often unmodified years later.
This is configuration rot. If your data center has been running for a while, the chances are pretty high that your cooling configurations, to name one example, are wildly out of sync. It’s even more likely you don’t know about it.
Every air conditioner is controlled by an embedded computer. Each computer supports multiple configuration parameters. Each of these different configurations can be perfectly acceptable. But a roomful of air conditioners with individually sensible configurations can produce bad outcomes when their collective impact is considered.
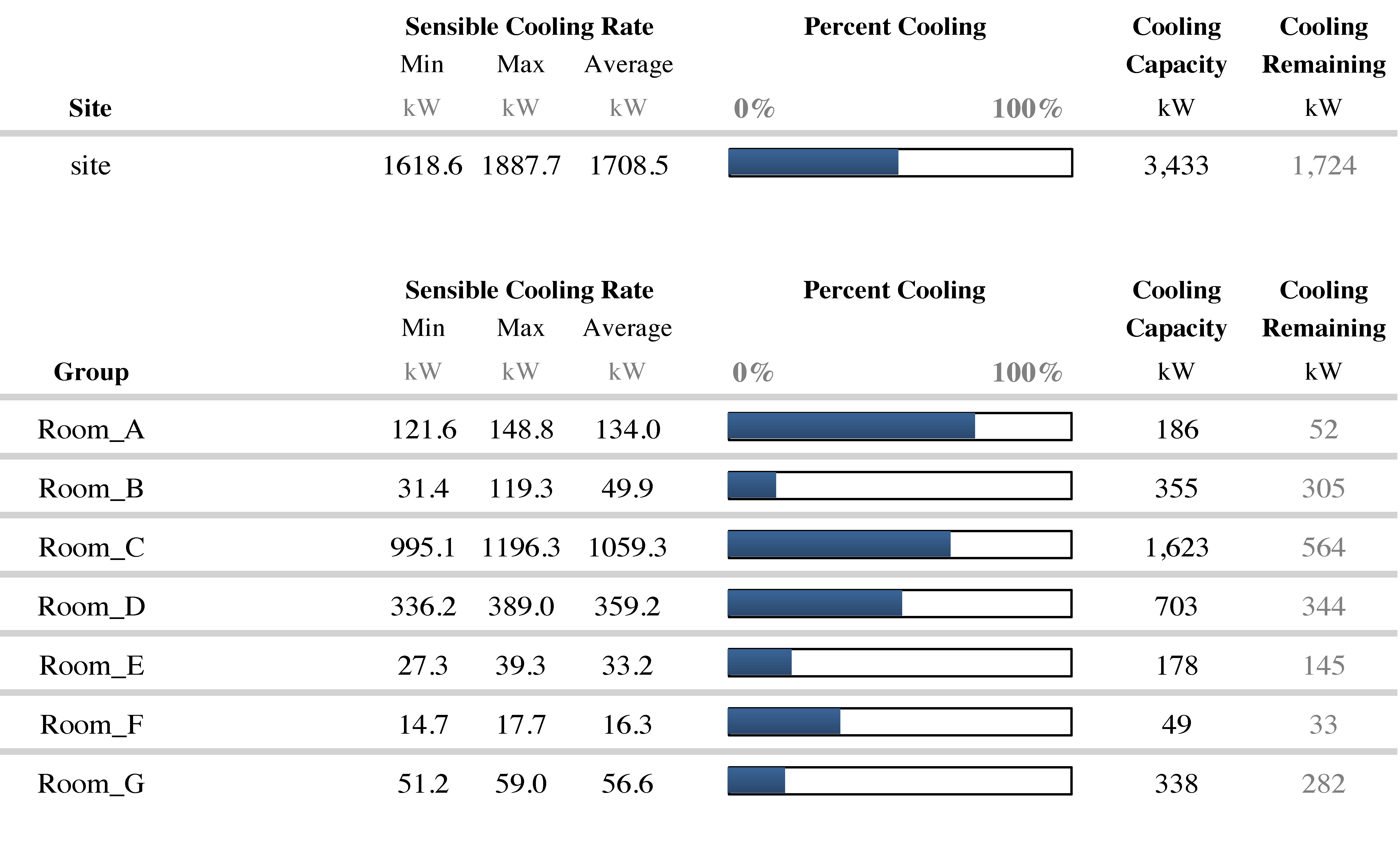
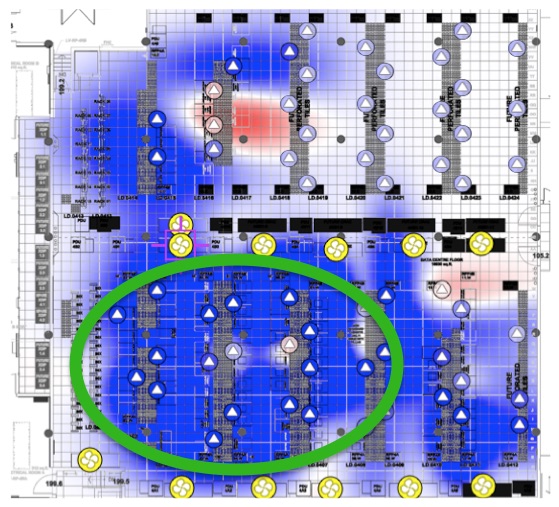
I recently toured a new data center in which each air conditioner supported 17 configuration parameters affecting temperature and humidity. There was a lot of unexplainable variation in the configurations. Six of the 17 configuration settings varied by more than 30%, unit to unit. Only five configurations were the same. Configuration variation initially and entropy over time wastes energy and prevents the overall air conditioning system from producing an acceptable temperature and humidity distribution.
Configuration errors contribute to accidental de-rating and loss of capacity. This wastes energy, and it’s costly from a capex perceptive. Perhaps you don’t need a new air conditioner. Instead, perhaps you can optimize or synchronize the configurations for the air conditioners you already have and unlock the capacity you need. Another common misconfiguration error is incompatible set points. If one air conditioner is trying to make a room cold and another is trying to make it warmer, the units will fight.
Configuration errors also contribute to poor free cooling performance. Misconfiguration can lock out free cooling in many ways.
The problem is significant. Large organizations use thousands of air conditioners. Manual management of individual configurations is impossible. Do the math. If you have 2000 air conditioners, each of which has up to 17 configuration parameters, you have 34,000 configuration possibilities, not to mention the additional external variables. How can you manage, much less optimize configurations over time?
Ideally, you need intelligent software that manages these configurations automatically. You need templates that prescribe optimized configuration. You need visibility to determine, on a regular basis, which configurations are necessary as conditions change. You need exception handling, so you can temporarily change configurations when you perform tasks such as maintenance, equipment swaps, and new customer additions, and then make sure the configurations return to their optimized state afterward. And, you need a system that will alert you when someone tries to change a configuration, and/or enforce optimized configurations automatically.
This concept isn’t new. It’s just rarely done. But if you aren’t aggressively managing configurations, you are losing money.