In 2014 we leveraged the significant company, market and customer expansion we achieved in 2013 to focus on strategic partnerships. Our goal was to significantly increase our global footprint with the considerable resources and vision of these industry leaders. We have achieved that goal and more.
Together with our long-standing partner NTT Facilities, we continue to add power and agility to complementary data center product lines managed by NTT in pan-Asia deployments. In partnership with Schneider Electric, we are proud to announce the integration of Vigilent dynamic cooling management technology into the Cooling Optimize module of Schneider Electric’s industry-leading DCIM suite, StruxureWare for Data Centers.
Beyond the technical StruxureWare integration, Vigilent has also worked closely with Schneider Electric to train hundreds of Schneider Electric sales and field operations professionals in preparation for the worldwide roll-out of Cooling Optimize. Schneider Electric’s faith in us has already proven well-founded as deployments are already underway across multiple continents. With the reach of Schneider Electric’s global sales and marketing operations, their self-described “Big Green Machine,” and NTT Facilities’ expanding traction in and outside of Japan, we anticipate a banner year.
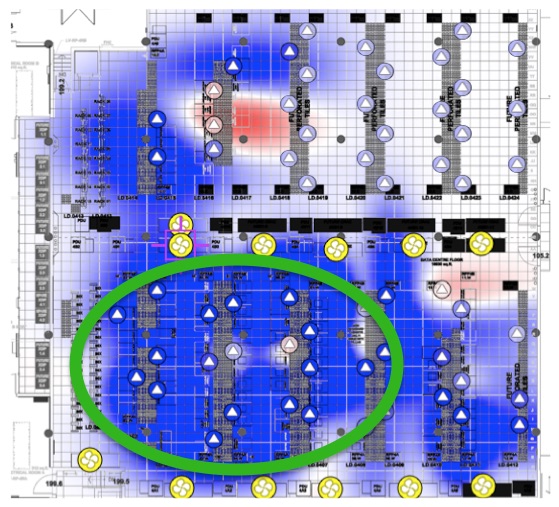
As an early adopter of machine learning, Vigilent has been recognized as a pioneer of the Internet of Things (IoT) for energy. Data collected over seven years from hundreds of deployments continually informs and improves Vigilent system performance. The analytics we have developed provide unprecedented visibility into data center operations and are driving the introduction of new Vigilent capabilities.
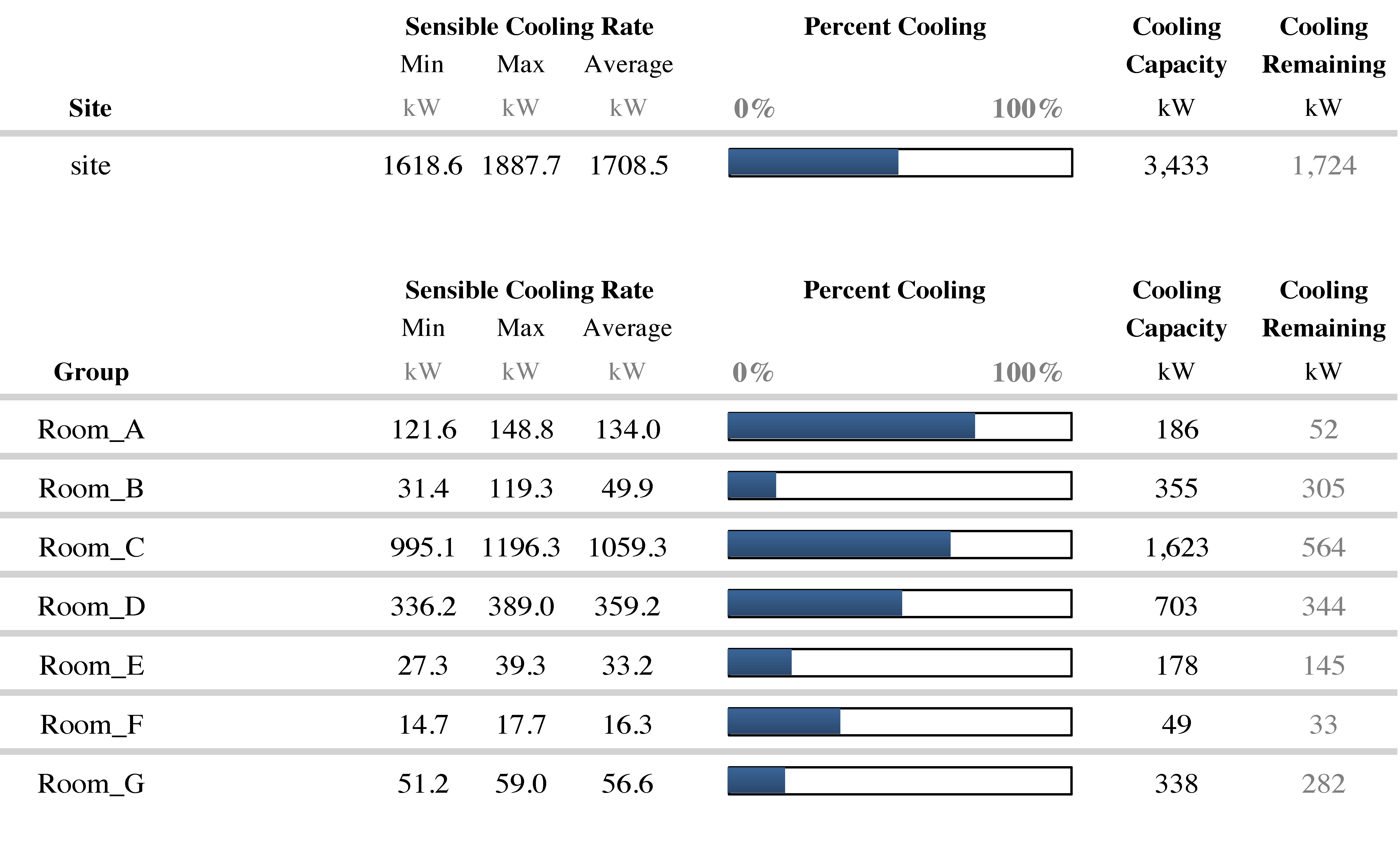
Business success aside, our positive impact on the world continues to grow. In late 2014, we announced that Vigilent systems have reduced energy consumption by more than half a billion kilowatt hours and eliminated more than 351,000 tons of CO2 emissions. These figures are persistent and grow with each new deployment.
We are proud to see our customers turn pilot projects into multiple deployments as the energy savings and data center operational benefits of the system prove themselves over and over again. This organic growth is testimony to the consistency of the Vigilent product’s operation in widely varying mission critical environments.
Stay tuned to watch this process repeat itself as we add new Fortune 50 logos to our customer base in 2015. We applaud the growing sophistication of the data center industry as it struggles with the dual challenges of explosive growth and environmental stewardship and remain thankful for our part in that process.